原题连接
世界杯特别场 TopCoder Marathon 101: World Cup MM 地址.
问题简述:
- 给你30个球员,球员$i$有3个属性,$atk_i$(进攻)、$def_i$(防御)、$agg_i$(犯规);
- 每个球员是3种职业之一,$F$前锋、$M$中锋、$D$后卫(不考虑门将);
- 一个球员如果职业是前锋,那么$atk$属性乘$2$,$def$属性置$0$;如果是中锋数值不变;如果是后卫$def$属性乘$2$,$atk$属性置$0$;
- 你只需要分配除门将以外的10个位置的候选人,比如:第$p$个位置候选人为$List_p$;
- 每个人可以属于多个候选位置(这条信息非常容易漏掉,问题没有刻意强调,实际是可以的);
- 但每个位置只能分配同一种职业,也就是当前上场的候选人只能以这种身份上场结算;
- 场面上的队伍的得分计$Score=min(sum(atk{player}), sum(def{player}))$;
- 赛场分5阶段进行,第一阶段按你排出的10个位置的候选人表的每个位置的第一个选手上场,之后每一场进行一轮结算,对每个选手按$agg_i$属性进行随机,随中了就吃一张黄牌,2张黄牌就下场,另外每个人还有$rate$的几率受伤下场($rate \in (0, 0.05)$);
- 如果一个队员下场了,那么立刻从其候选列表找出下一个没有出现过的队员上场(注意:一个队员可能在别的候选集已经提前上场了)
- 另外,这个问题中提供了一些阵容的概念,即在场的队员中拥有某个$group_j$集合里的全部球员,那么这些球员的基础属性分别增加$atk_j$、$def_j$、$agg_j$;
- 注意几点:$atk_j$、$def_j$、$agg_j$可能有正有负;每个人都加这么多,且在结算前锋时用$2*(atk_i + atk_j)$,同理后卫;一个人可能同时属于多个阵容,那么就每个阵容的加成都获得;
- 优化目标:5轮结算完成后,取5次结算后的总积分作为本次比赛的得分,得分越大越牛逼。
赛程回顾
这场比赛参与的人数不多,估计又和随机有关,不过这个问题其实受随机因素影响并不大,其标准差只有均值的5~7%左右,所以不用太考虑one hit问题也不会太坏。
因为最近加班已进入疯狂状态,导致我能调试的时间非常少,大多时候只能利用休息的间隙在脑海里yy一些思路。其实,也并没想出什么牛逼的方法,只用了一些中规中矩“随大流”的方法来处理,其实结果还不错。大致来说就是分阶段分别进行:快速海选种子解,对种子解进行粗过滤选出精英解,对精英解进行爬山选出最优精英,再把剩余的时间用在这个解的迭代上。
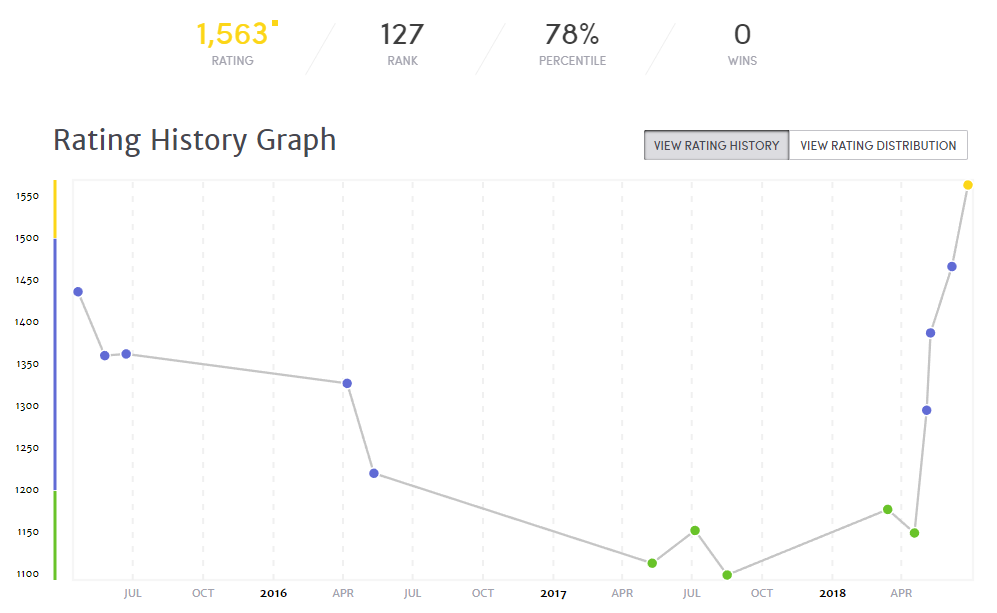
最后排11,还算满意。可惜的是对问题的理解上有一些偏差,并不知道每个选手可以分配在多个候选人集合里,错过了一些更优解。不然可能能进前十,略遗憾。不过这场过后marathon rating也终于进入yellow coder了,期待rating能继续涨下去,今年涨势真是喜人。
思路梳理
问题的评估:
- 这个问题严格上来说,每个位置安排3-4个人基本就足够了,因为首先比赛只有5轮,而每轮每个位置一个球员受伤的概率平局只有2.5%,也就是整场比赛平均只有1-2个人因受伤淘汰,另一方面,犯规要2轮才淘汰,即每组成员最多能被淘汰两个人,所以安排3~4个人基本能满足全场不会缺人的状态。实际测试表明,一般情况下,整场比赛极大概率不会超过3个人被替换。
- 所以,我们可以把搜索的精力集中在首发阵容和每个位置的前2个替补队员身上即可。
我的主要策略:
不过我在比赛过程中,对题目有一些误解,主要是没有发现一个队员可以放在多个替补的位置上,这使我缺少了一个优化方向,因为数据好的替补队员,你要让他有更大的几率上场才行。
言归正传,虽然有一些错误的理解,但基本不影响整个方案的实施与运行。
首先,将问题分为3个主要阶段:
- 第一阶段,搜索尽可能好的首发阵容,包括,10个成员是谁,以及每个成员的赛场位置(F、M、D),赛选出$top K$的候选集;
- 第二阶段,对第一阶段挑选出的首发阵容的成员,按贪心的思路依次补全前$k$个候选集方案的替补队员,并进行若干次比赛的随机模拟,将成绩最好的$top M$个队伍挑出来;
- 第三阶段,对最好的$top M$的队伍,分别进行基于模拟退火的迭代操作,使其获得更好的表现,最终去除最优的一个座位解输出。
具体的细节总结:
-
第一阶段的搜索如何评价? 只进行5轮模拟中的第一轮模拟,计算分数即可。
这里算分有个小技巧:
你可以把FMD标记为job=0,1,2,那么一个人的$real\_atk = atk (2 - job)$ 以及$real\_def = atk job$。
这个技巧可以便于后期的模拟退火的迭代加速。 -
第二阶段的如何构造一个阵容? 随机!${n \choose k}$,而$job$采用梯度下降来迭代。
这里有个在蒙特卡洛方案下减小迭代成本的技巧,只针对job的迭代有效。
我们可以先用蒙特卡洛模拟$N$次,并记住每次每轮每个位置上队员的$atk$与$def$值,记为atk[simu_id][round_id][pos],def[simu_id][round_id][pos].我们在改变某个位置pos对应的job时,只需要枚举simu_id与round_id并计算atk与def的变化差值即可。diff = new_job - job; _t_atk[simu_id][round_id] = atk_sum[simu_id][round_id] + atk[simu_id][round_id][pos] * diff; _t_def[simu_id][round_id] = def_sum[simu_id][round_id] - def[simu_id][round_id][pos] * diff; _t_scores[simu_id] += min(_t_atk[simu_id][seg], _t_def[simu_id][seg]);这个优化方案可以只采用一个蒙特卡洛就进行局部优化,但是注意因为随机的原因小小过拟合问题。因为数据不是完备的,所以迭代出来是基于这个数据集的。
-
第三阶段怎么迭代? 模拟退火的操作,只有一种:交换某两个球员的位置,并相应的用第二阶段的方法迭代job,并将最优解作为这个迭代的解。
-
主要的提升来源于第二阶段的这个低成本迭代job的方法,这使得问题在job这个维度上复杂度大大降低,以至于几乎不需要成本进行计算。
被遗漏的优化点:
-
其实这个问题已经做得很不错了,不过丢失了一个关键的信息,就是一个替补可以在不同的队伍里。这样可以把顶级后卫或前锋尽可能排在各个替补的前面。其实最后和排第一的选手差距并不大,可能主要缺的就是这里了。略遗憾。
-
这次大佬们好像没提供太多启发性思路,就不总结了。