因为最近做一些东西,需要比较输入的简笔画与给定标准是否相似,恰好试了一下shape contexts方法,干脆写个日志简单记录一下。
- 论文《Shape Context: A new descriptor for shape matching and object recognition》
- Shap Contexts字面翻译就是形状上下文。
- 其设计目的:对比两个简单的形状的相似度。(1、直接用来识别复杂形状是不行的;2、但可以作为形状识别的一组强特征和其他方法融合)
核心算法框架
如果不考虑细节,算法的大致框架大致如下:
- 形状A,采样点集$SA = [ pa[i] ... ]$
- 形状B,采样点集$SB = [ pb[j] ... ]$
- $ForEachPair( pa[i], pb[j] )$,计算:
- $Cost(i, j) = CostFunc( SCF(pa[i], SA), SCF(pb[j], SB))$
- (其中, $SCF$是计算单点ShapeContext的, $CostFunc$ 是计算两个单点上下文误差的)
- 对Cost矩阵构成的二分图,求最佳匹配,使总权重和最小。
- (即试图给$SA$中每个$pa[i]$找到$SB$中最相近的点$pb[j]$,并使全局最优)
- 该最小总权重就可以评价A、 B两个形状的相似度。
SCF计算方法
$SCF(pa_i, SA)$简单说就是以待计算点$pa_i$为中心,做一个极坐标下的“网格”,然后统计每个区域(格子)内采样点的个数。将每个格子的统计值作为向量,就是一个点的形状上下文了。
看下图好理解一些:
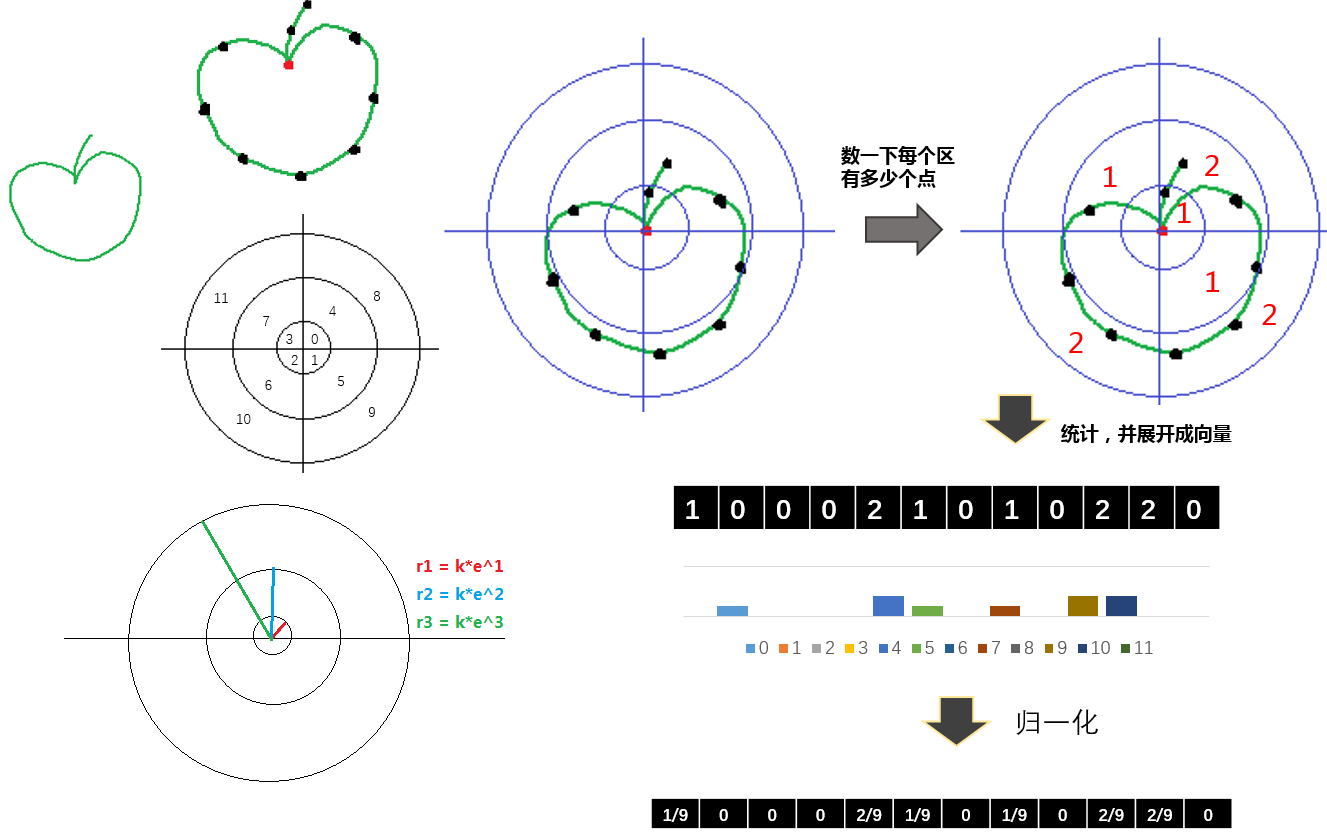
- 注意点:
-
- 网格每一环的半径是按指数级上升的,上图为了表达画的没那么指数级。
-
- 每一环网格分多少个区比较好呢?实践来看12个是比较好的结果(上图里是4个,当然也是为了示意而已,如果真的用4个可能效果不会非常理想)
CostFunc实现
论文用了χ2 test,这个可以wiki一下
具体实现就是:
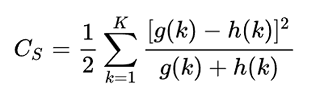
- 简单说就是:就是求两个分布之间的差异值
二分图最佳匹配
目前最稳的方法是 $O(n^3)$ 的KM。网上很多blog介绍,就不解释了。
- 到这里算法主干已经介绍结束,但是还有一些细节需要解决
其他问题与解决
- 形状大小问题
这个采用归一化的方法,将整张图片按所有采样点间的平均距离压缩。
这样处理后,将能避免缩放和平移对计算产生的误差影响。
- 有效的额外的特征
一个点除了用周围节点的分布外,还可以加入该节点的切线角度,作为另一个重要特征。一个节点的切线夹角,可以用轮廓上周围点的最小二乘的直线来计算。
两个不同的切线夹角$\theta_i$与$\theta_j$的距离计算方法:
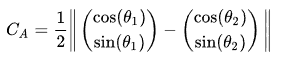
把这项和节点的ShapeContext按权重加成即可。(据说对数字识别有效)
- Shape context distance
通过TPS变换可以得到点集Q到P的映射。那么可以计算该距离为:
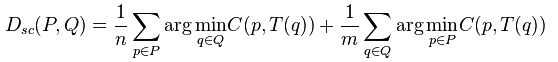
形状距离
- 三部分构成:Shape context distance, Appearance cost 以及 Transformation cost
- 都是公式懒得解释了,也不算核心key idea,以后有空写的话,再说吧。
- 以下是wiki里的描述:

简单实现
-
用c++实现一个python库,python直接调用+画图验证。
-
用前面的草稿苹果为例,先来个像的:
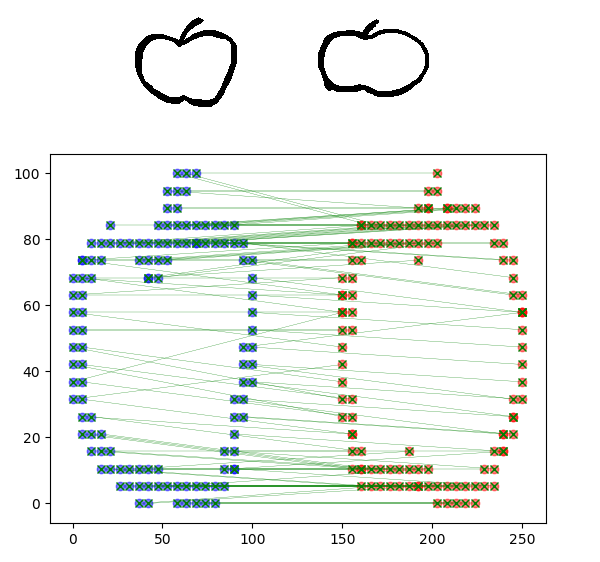
-
再来些人眼下不是很像的:
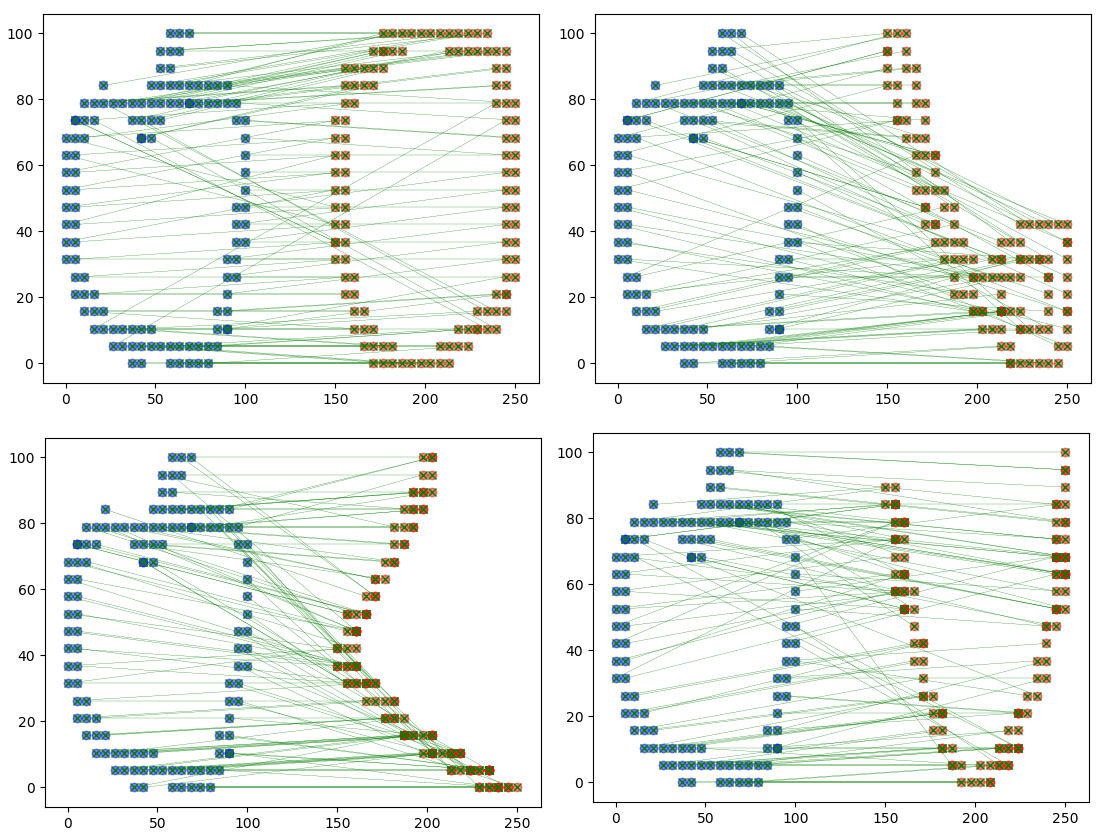
-
实际上不难发现越相似“平行线”越多,越不像交叉线越多